V dnešnom digitálnom svete je efektívne získavanie informácií z webových stránok častokrát výzvou. Jedným z riešení, ktoré sa objavuje v kontexte ochrany pred automatizovaným zberom dát (scrapingom), je koncept "Kouzelný cop", ktorý naznačuje implementáciu mechanizmov na odhalenie a znevaženie scraperov.
Kľúčové princípy ochrany pred scrapingom
Základná myšlienka spočíva v tom, že aj keď dodatočná záťaž na jednotlivých úrovniach môže byť zanedbateľná, pri masovom scrapingu sa tieto náklady kumulujú a výrazne predražujú celý proces pre automatizovaných zberačov dát.
Techniky odhaľovania a identifikácie
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
V tomto kontexte je dôležité zamerať sa na pokročilé techniky ako je fingerprinting (odtieň odtlačkov prstov) a identifikácia bezhlavých prehliadačov. Jedným zo spôsobov, ako to dosiahnuť, je analýza spôsobu, akým tieto prehliadače pracujú s vykresľovaním fontov (písma).
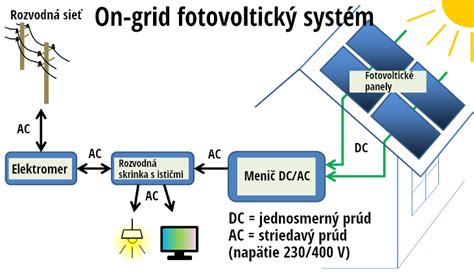
Cieľom je, aby sa stránka s výzvou "proof of work" (doklad o práci) nemusela zobrazovať používateľom, ktorí s oveľa vyššou pravdepodobnosťou predstavujú legitímnych návštevníkov.
Obmedzenia moderných technológií
Je dôležité poznamenať, že systémy ako Anubis, ktoré sú navrhnuté na implementáciu týchto ochranných mechanizmov, vyžadujú použitie moderných funkcií JavaScriptu. Tieto funkcie môžu byť deaktivované v pluginových rozšíreniach prehliadačov, ako je napríklad JShelter. To môže predstavovať výzvu pre používateľov, ktorí sa spoliehajú na tieto nástroje na zvýšenie svojej online anonymity a bezpečnosti.
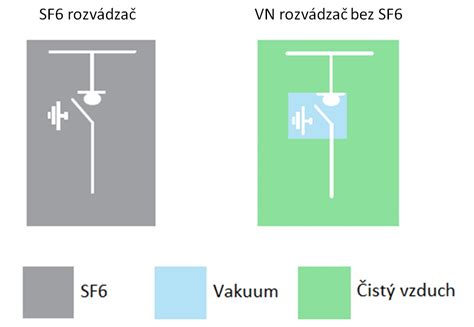
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.

The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
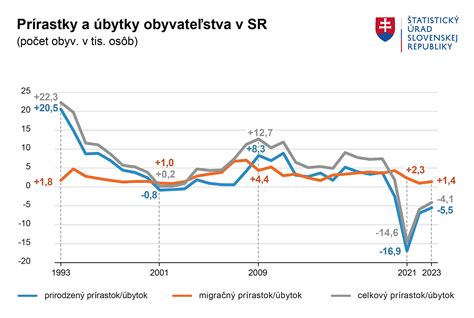
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.
The idea is that at individual scales the additional load is ignorable, but at mass scraper levels it adds up and makes scraping much more expensive.
Ultimately, this is a placeholder solution so that more time can be spent on fingerprinting and identifying headless browsers (EG: via how they do font rendering) so that the challenge proof of work page doesn't need to be presented to users that are much more likely to be legitimate.
Please note that Anubis requires the use of modern JavaScript features that plugins like JShelter will disable.